

Give me 2 minutes, and I’ll tell you why Kubernetes is irreplaceable
One pod crash. A moment of panic. And then... the real magic happened.

Welcome again to the AKVAverse, I’m Abhishek Veeramalla, aka the AKVAman, your guide through the chaos
Let me take you back to a moment that changed the way I look at infrastructure forever
I was working a late-night on-call shift. Everything was running fine until suddenly, a critical pod in production turned red 🔴
My heart sank. I froze. I opened my terminal, ready to jump into the logs and troubleshoot like mad.
But before I even hit enter, the pod was green again.
Healthy.
Alive….
I hadn't done anything.
Kubernetes had already fixed it.
The night I realized Kubernetes wasn't just a tool, it was a platform that refuses to die.
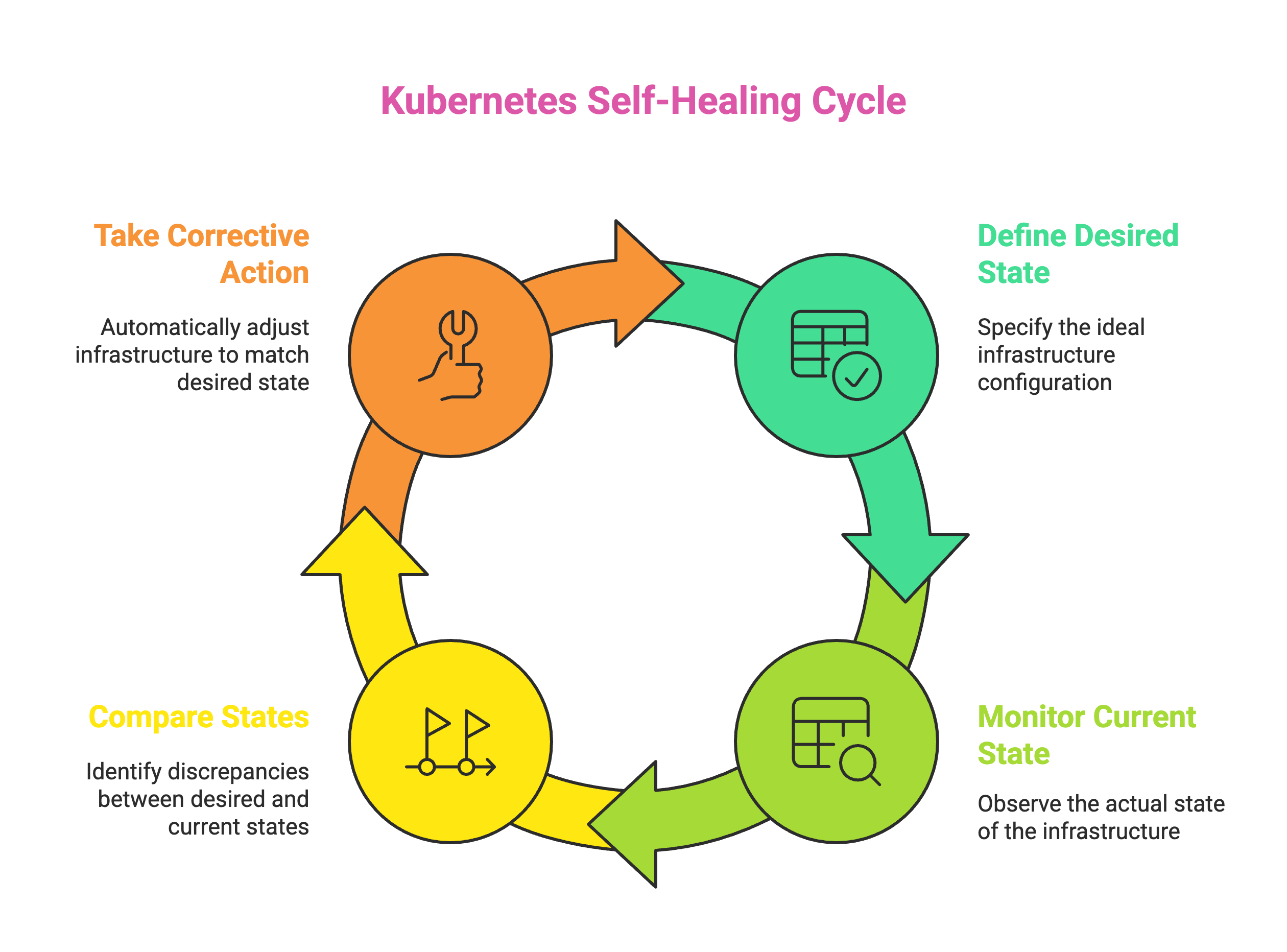
Now let’s understand what happened behind the scenes.
The core of Kubernetes’ self-healing lies in health probes, pod lifecycle management, and the controller reconciliation loop.
How Kubernetes Heals Itself Behind the Scenes
So, how does Kubernetes pull off this magic trick? It all boils down to a few key concepts
Liveness and Readiness Probes: The Health Checkers
Think of liveness and readiness probes as Kubernetes' built-in health checkers. They constantly monitor the health of your pods and containers.
Liveness Probe
A liveness probe in Kubernetes is used to determine whether a container is still running properly. If the liveness probe fails repeatedly, Kubernetes assumes the container is stuck or in a failed state, and it will automatically restart the container to restore normal operation.
Question: Is the app alive internally?
Answer:If this check fails (e.g., infinite loop, unresponsive backend), Kubernetes kills and restarts the container inside the pod.Readiness Probe
A readiness probe checks if a container is ready to receive requests. Unlike liveness probes, if this check fails, Kubernetes doesn’t restart the container; it simply removes the pod from the load balancer’s endpoints, so traffic is not routed to it until it’s ready again.
Question: Is the app ready to serve users?
Answer: If this fails, Kubernetes simply removes the pod from the Service endpoint list meaning no traffic is routed to it until it recovers.The syntax of it
livenessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 3
periodSeconds: 10
readinessProbe:
httpGet:
path: /readyz
port: 8080
initialDelaySeconds: 5
periodSeconds: 10
Desired State Management: The Blueprint for Immortality
Kubernetes gave us something revolutionary: the ability to define our infrastructure not as a set of manual steps, but as a desired outcome.
Instead of writing scripts to fix things when they go wrong, we simply declare how things should be. We specify how many replicas we want running, how much CPU and memory each pod should use, what container image to run, and what configurations to apply.
And Kubernetes does the rest.
I’ve seen it play out in real time. A pod crashes? Kubernetes notices. It doesn't wait for alerts or engineers to step in. It immediately replaces the failed pod to maintain the correct number of replicas.
When a node goes down, maybe due to hardware issues or cloud hiccups, Kubernetes identifies which pods were affected and reschedules them to healthy nodes in the cluster. It does all this without panic, without delay, and without any manual effort from us.
This continuous loop of comparing the current state with the desired state and taking corrective action is what gives Kubernetes its immortality.
It’s not just automation.
It’s autonomy.
And that’s what makes Kubernetes truly self-healing.
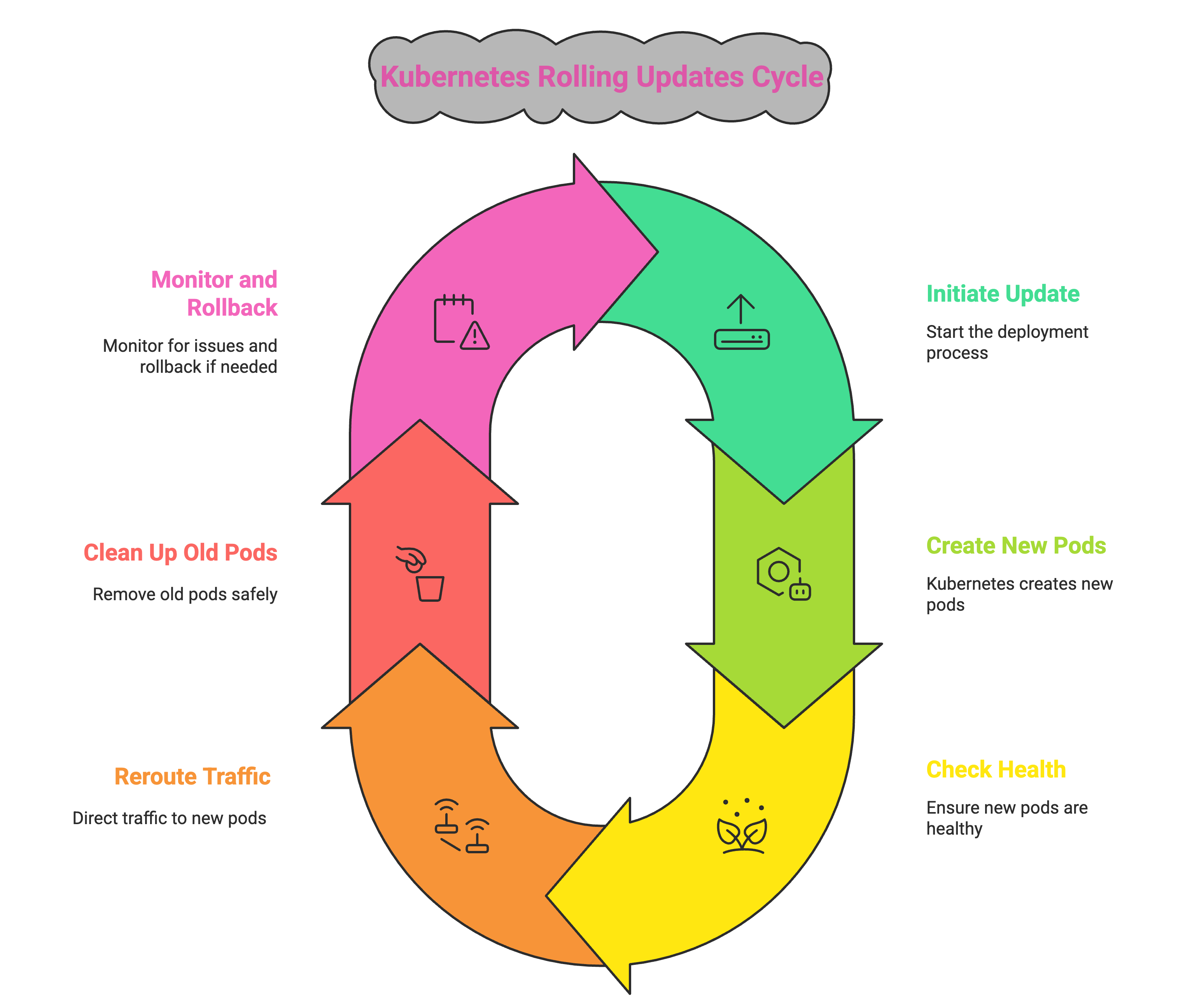
Zero-Downtime Deployments: The Art of the Rolling Update
Shipping code is exciting, but in traditional systems, it often comes with fear
"Will this update break production?
"What if users experience downtime?"
That fear used to be real for all of us. But then came Kubernetes, and it flipped the game with something called rolling updates
With rolling updates, Kubernetes gave us a way to update our applications without ever taking them offline. It doesn’t rush. It doesn’t take down everything at once. Instead, it replaces our old pods gradually, one at a time, while keeping enough healthy ones online to serve users during the transition.
The first time I did this in production, I remember watching the pods shift in and out like clockwork. There was no interruption, no service degradation—just smooth, reliable progress. It felt like magic
Just one command, and Kubernetes takes over—creating new pods, checking their health, rerouting traffic, and cleaning up the old ones only when it’s safe.
And if something goes wrong? Kubernetes can roll back. Instantly for us.
This is how we deploy now, not with fear, but with trust in a system that has our backs. Rolling updates have become part of our everyday DevOps playbook, and honestly, I can’t imagine working without them.
Bonus: Teaching Kubernetes Our Language with CRDs
As I got more comfortable with Kubernetes, something began to click.
We were already seeing how it could heal itself, balance workloads, and recover from disasters. But I started asking myself
What if we wanted Kubernetes to manage things that didn’t come built-in, things specific to our world?
That is when I discovered Custom Resource Definitions, or CRDs. And honestly, it changed the way I looked at Kubernetes all over again.
Custom Resource Definitions (CRDs) are a way to extend the Kubernetes API without modifying the Kubernetes source code. They allow you to define your custom resources, which are essentially new Kubernetes objects that you can create, read, update, and delete (CRUD operations) just like built-in resources like Pods, Services, and Deployments.
In MLOps, they let you manage training jobs, models, and pipelines like native Kubernetes resources.
In AI systems, CRDs can represent inference endpoints, feature stores, or retraining triggers, bringing intelligent workflows under Kubernetes control.
In DevOps, CRDs help you automate deployments, provision infrastructure, and control complex rollouts.
With CRDs, you teach Kubernetes to understand and manage what matters most to you.

That late-night recovery moment? It flipped my mindset. Kubernetes isn't just a platform; it’s our always-on, self-healing partner in shipping confidently at scale. From zero-downtime rollouts to custom CRDs, we’ve stopped babysitting infra and started building the future. This is what modern DevOps feels like, and trust me, you want in.
So start small, stay curious, and get hands-on.
Until next time, keep building, keep experimenting, and keep exploring your AKVAverse. 💙
Abhishek Veeramalla, aka the AKVAman
Hi Abhishek your content design took me to visual treat while reading through the article… awesome post…
Great article Abhishek. This is really amazing, it was like a movie was playing in front of me. Awesome explanation 👏🏽