

Kubernetes Autoscaling: HPA Vs VPA
Pods in Motion When to Multiply, When to Amplify

Hello
Welcome again to the AKVAverse, I’m Abhishek Veeramalla, aka the AKVAman.\
Today, we will be discussing Kubernetes autoscaling, focusing on Horizontal Pod Autoscaling (HPA) and Vertical Pod Autoscaling (VPA). We will explore the challenges of managing fluctuating workloads and the benefits of autoscaling to manage them. Additionally, we will learn about how HPA and VPA can be a lifesaver from a cost perspective, as well as keeping your system up and running.
The Scaling Challenge
Managing an application means dealing with a workload that is rarely constant. Your traffic might spike during a product launch or a holiday sale, only to become very quiet in the middle of the night. Trying to manually allocate resources for these fluctuating scenarios is a significant challenge.
If you provision for peak traffic all the time, you're wasting money on idle resources. However, if you provision only for average traffic, your application will likely crash during a demand spike, leading to a poor user experience and lost revenue.
The era of manual resource scaling ends now. The Kubernetes Autoscaling technique of HPA and VPA ends the manual resources scaling, whether you are dealing with high traffic on a Sunday sale or in the middle of the night, where your application experiences low traffic. Kubernetes holds your back.
HPA (Adding More Hands)
HPA (Horizontal Pod Autoscaler): Automatically changes the number of running pods to handle changes in load.
Your application's traffic can be unpredictable, and that's where the Horizontal Pod Autoscaler, or HPA, becomes essential for you.
Here’s a simple way to understand it: Imagine your workload is a heavy weight. Instead of trying to make one person stronger to lift it, you simply bring in more people to help. That’s exactly what HPA does for your application. When a metric you're watching, like CPU usage, goes over a limit you've set, HPA automatically adds more pods to share the load. It's a straightforward and effective way for you to handle sudden spikes.
The best part for you, though, is what happens when your traffic dies down. HPA is smart enough to see the load is gone, and it automatically starts removing those extra pods, so you don’t have to intervene at all. From a budget standpoint, this will be a game-changer. It ensures you are only paying for the server resources your application is actually using. You'll feel a huge relief when you're no longer wasting money on idle capacity during your slower periods, like in the middle of the night.

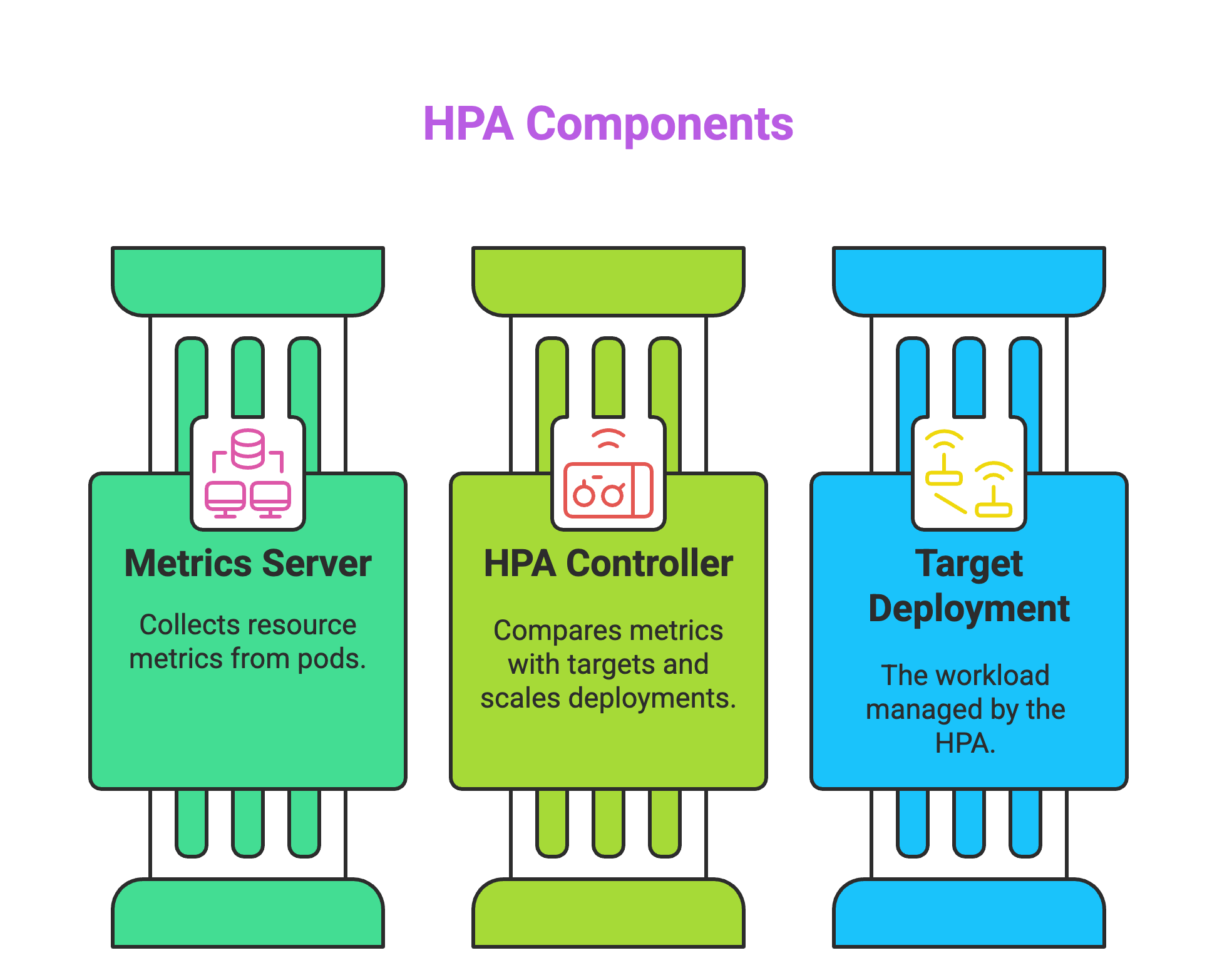
There are mainly 3 components of HPA:
Metrics Server: Collects resource metrics like CPU and memory from the pods.
HPA Controller: The control loop that compares metrics with the target and scales the deployment up or down.
Target Deployment/StatefulSet: The workload that the HPA is managing.
spec:
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50VPA (Building Bigger Muscles)
VPA (Vertical Pod Autoscaler): Automatically adjusts the CPU and memory resources of existing pods to match their needs.
Now, let's look at scaling from a different angle with the Vertical Pod Autoscaler, or VPA. This approach isn't about adding more pods; it's about making your existing pods fundamentally more powerful. Imagine that instead of calling in a whole crew to lift a heavy weight, you have one bodybuilder who's strong enough to handle it all alone. That's exactly what VPA does for your application. It watches how your pods are performing, and if one is constantly struggling for more CPU or memory, VPA automatically gives it a bigger resource allocation to handle the job.
The real advantage is how VPA helps you stop wasting money, a concept often called "right-sizing." Think about how many times you've had to guess at resource limits. You might give a pod 2 CPU cores just to be on the safe side, only to find out later it barely uses half a core. You end up paying for a lot of power that just goes to waste. VPA gets rid of that guesswork. It learns what your application needs over time and adjusts the resources to match, making your whole setup more efficient and saving you money.

There are mainly 3 components of VPA
Recommender: Analyses historical and current pod usage to suggest new resource values.
Updater: Evicts pods that need resource changes so they can be recreated with the updated values.
Admission Controller: When the new pod is created, it applies the recommended resources.

spec:
resourcePolicy:
containerPolicies:
- containerName: "*"
minAllowed:
cpu: "250m"
memory: "256Mi"
maxAllowed:
cpu: "1000m"
memory: "1Gi"Smart Scaling, Smarter Savings
Both HPA and VPA are powerful tools for automating Kubernetes resource management, but they solve the scaling problem in different ways. HPA is about handling load by changing the quantity of pods, while VPA is about optimizing the capacity of individual pods.
HPA (More Hands): Best for stateless applications that can easily scale out to handle traffic spikes.
VPA (Bigger Muscles): Ideal for stateful applications or jobs where adding more replicas isn't simple, and for right-sizing resource requests to optimize cost.

By implementing these autoscaling strategies, you move from a reactive, manual management model to a proactive, automated one. This not only keeps your application stable and performant under any load but also provides significant cost savings by ensuring you never pay for more resources than you need.
So start small, stay curious, and get hands-on.
Until next time, keep building, keep experimenting, and keep exploring your AKVAverse. 💙
Abhishek Veeramalla, aka the AKVAman
Insightful..thnx
Great work Abhishek what a clean clear concise article on HpA/Vpa loved it